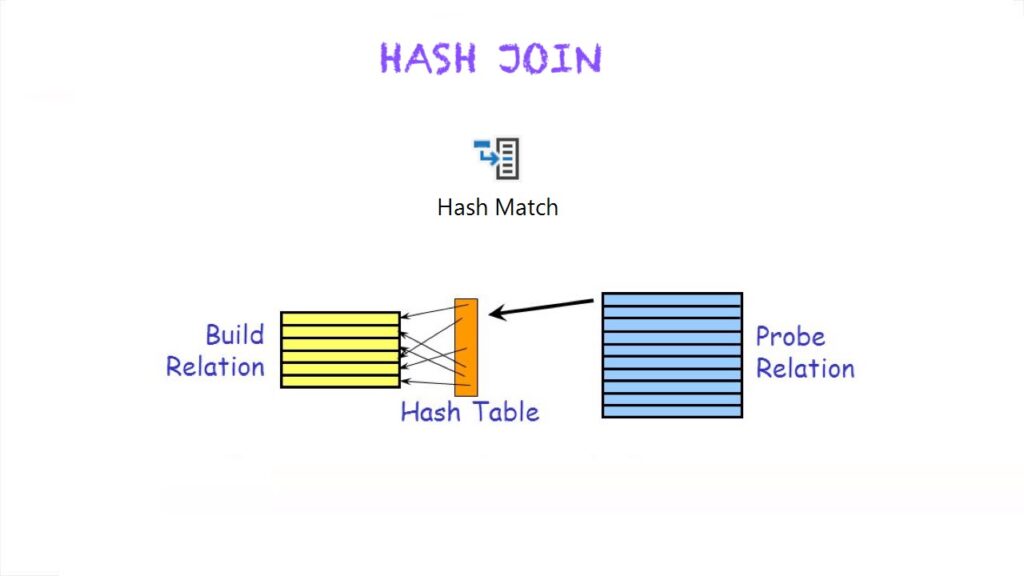
A DB2 Hash Join is a type of join operation that uses a hash table to match rows from two or more tables. It is particularly beneficial when joining large tables or when the join condition involves non-indexed columns. The basic idea is to divide the rows of each table into small groups, called “buckets,” based on the values in a specific column or set of columns. These columns are known as the “join keys.” When performing this join, DB2 first builds a hash table for one of the tables, using the join keys as the hash keys. It then scans the other table, using the join keys to look up matching rows in the hash table. Any rows that match are then returned as the result of the join.
The syntax is similar to the syntax for other types of joins. You specify the tables to be joined, along with the join condition and the columns to be returned in the result set.
SELECT column1, column2, ... FROM table1 JOIN table2 ON table1.join_key = table2.join_key
In this example, table1 and table2 are the tables to be joined, and join_key is the column or set of columns that will be used as the join keys. The ON clause specifies the join condition, which tells DB2 how to match rows from the two tables. The SELECT clause specifies the columns to be returned in the result set.
It’s also possible to specify more options for the join, such as the type of join, like in this example:
SELECT column1, column2, ... FROM table1 JOIN table2 ON table1.join_key = table2.join_key WITH HASH JOIN
This query will force the use of a hash join, even if DB2 would have chosen a different join method based on the query optimizer. It’s worth noting that the syntax can vary slightly depending on the version of DB2 and the programming language you are using to interact with the database.
Advantages and disadvantages of DB2 Hash Join
There are several advantages:
- Efficiency: Hash joins are particularly efficient when one of the tables is much smaller than the other. The smaller table can be used to build the hash table, allowing the join to be completed quickly.
- No need for indexes: Hash joins can be useful when the join keys are not indexed, as the hash table can be built in memory rather than having to scan the table on disk.
- Good with large data sets: Hash joins can handle large data sets well, as they can divide the rows into small groups and process them in parallel.
- Good with skewed data: Hash joins can also be beneficial when there is a large imbalance in the number of rows that match the join condition, known as skewed data.
- Good for non-equi joins: Hash joins are good for non-equi joins, which means that the join condition is not just an equality operator.
- Good for data partitioning: Hash join can also be used for data partitioning, improving a query’s performance.
- Good for parallel processing: Hash joins can be performed in parallel, which can further improve performance for large data sets.
While DB2 hash joins have many advantages, they also have some disadvantages:
- Memory requirements: Hash joins can be memory-intensive, as the entire hash table must be built-in memory. This can be a problem when working with very large data sets or when there is limited memory available.
- CPU requirements: Hash joins also require more CPU resources than other types of joins, as the hash function must be applied to each row. This can be an issue when working with large data sets or when the CPU is already heavily utilized.
- Limited to equip-joins: Hash joins are limited to equijoin, which means join conditions that are based on equality operators only. In the case of a non-equi join condition, other join methods should be used.
- Limited to single-column join: Hash joins are typically limited to joining on a single column or set of columns, while other join types can handle multi-column joins.
- Limited to inner join: Hash joins are typically used for inner join, while other join types can be used for outer joins as well.
- Limited to certain data types: Hash joins are typically limited to certain data types, such as integers and strings. Other data types, like floating point numbers, may not be suitable for use as join keys.
Performance improvement for Hash JOIN in DB2
- Use appropriate join keys: Using appropriate join keys is crucial for the performance of a hash join. The join keys should be chosen such that they have a good distribution of values and are not skewed.
- Use indexes: Creating an index on the join keys can improve the performance of a hash join, as the index can be used to locate the matching rows more quickly.
- Use the right join method: DB2 uses a cost-based optimizer to choose the join method based on the query, data distribution, and statistics. However, if you have knowledge of the data distribution and the query, you can use the right join method, like forcing to use hash join, to improve performance.
- Increase the sort heap: Increasing the sort heap can improve the performance of the hash join. The sort heap is the memory used by DB2 for sorting and hashing operations.
- Use parallel processing: It can be performed in parallel, which can further improve performance for large data sets. By default, DB2 will use parallel processing if the query qualifies, but you can also specify the degree of parallelism to use.
- Monitor the performance: Monitor the performance of the query and the system resources used by the query. This will give you an idea of how much memory and CPU resources are being used, and you can fine-tune the query or the system accordingly.
- Update statistics: Make sure that the statistics of the table are up-to-date as it will help the optimizer to make better decisions about the join method.
Example of Hash Join
Let’s say we have two tables, orders and customers, with the following data:
orders: +----+---------+----------+----------+ | id | order_id| customer_id | +----+---------+----------+----------+ | 1 | 100 | 1 | | 2 | 101 | 2 | | 3 | 102 | 3 | | 4 | 103 | 4 | | 5 | 104 | 1 | +----+---------+----------+----------+ customers: +----+---------+---------+---------+ | id | name | city | +----+---------+---------+---------+ | 1 | John | New York | | 2 | Jane | London | | 3 | Michael | Paris | | 4 | Emily | Berlin | | 5 | David | Sydney | +----+---------+---------+---------+
We want to join these tables on the customer_id column so that we can see the customer name and city for each order.
SELECT orders.order_id, customers.name, customers.city FROM orders JOIN customers ON orders.customer_id = customers.id WITH HASH JOIN
This query joins the orders and customers tables on the customer_id column and selects the order_id, name, and city columns from the resulting table. The WITH HASH JOIN clause forces the use of a hash join.
The result of the query will be:
+---------+---------+---------+----------+ | order_id| name | city | +---------+---------+---------+----------+ | 100 | John | New York | | 101 | Jane | London | | 102 | Michael
Conclusion
In conclusion, hash join is a powerful join method in DB2 that can be used to efficiently join large data sets. The key to a successful join is choosing the right join keys and ensuring that the data is appropriately distributed. By following the performance improvement suggestions mentioned earlier, you can make the most of this powerful join method and improve the performance of your queries. However, it is also important to keep in mind that hash join has some disadvantages, like being limited to equijoin, limited to single column join, limited to certain data types, and limited to an inner join. Hence, it’s essential to consider the data and the query requirements to select the most appropriate join method.